Introduction to HERITRACE
HERITRACE (Heritage Enhanced Repository Interface for Tracing, Research, Archival Curation, and Engagement) is a semantic data editor designed for galleries, libraries, archives, and museums (GLAM) that bridges the gap between sophisticated semantic technologies and the practical needs of cultural heritage professionals.
The challenge
Section titled “The challenge”The widespread adoption of Semantic Web technologies in the GLAM sector has created a paradoxical situation. While these technologies have made human intervention more critical due to the semantic interpretation of data that cannot be automated, they have simultaneously limited the number of curators to those who are experts in the Semantic Web. This creates challenges in workforce scalability and accessibility.
Many GLAM institutions face a choice between embracing Semantic Web technologies (requiring staff with advanced technical expertise) or avoiding them entirely to prevent curatorial complexities. HERITRACE resolves this dilemma by enabling non-technical domain experts to manage semantic data intuitively without losing its semantic integrity.
Purpose and objectives
Section titled “Purpose and objectives”HERITRACE has been designed with five primary objectives:
- User-friendly interface: Providing an intuitive interface for domain experts to interact with semantic data without technical knowledge
- Comprehensive provenance management: Implementing detailed documentation of metadata modifications, including who made changes, when, and from what sources
- Robust change-tracking: Delivering efficient version control capabilities for reconstruction of previous data states
- Flexible customization: Offering standardized configuration through SHACL and YAML rather than proprietary solutions
- Seamless integration: Facilitating compatibility with pre-existing RDF data collections without modification
Target users
Section titled “Target users”End users (GLAM professionals)
Section titled “End users (GLAM professionals)”- Librarians managing bibliographic records
- Archivists cataloguing collections
- Museum curators organizing metadata
- Academic researchers working with bibliographic data
Domain experts can enrich and edit metadata through an intuitive interface without knowing anything about the Semantic Web, while the system maintains complete semantic integrity behind the scenes.
Technical users (developers and system administrators)
Section titled “Technical users (developers and system administrators)”- System administrators deploying and maintaining HERITRACE
- Developers customizing schemas through SHACL definitions
- IT professionals configuring YAML display rules and database connections
Technical staff can customize HERITRACE through standardized languages (SHACL for data validation, YAML for interface configuration) rather than learning proprietary templating systems.
Key features
Section titled “Key features”Provenance management and change tracking
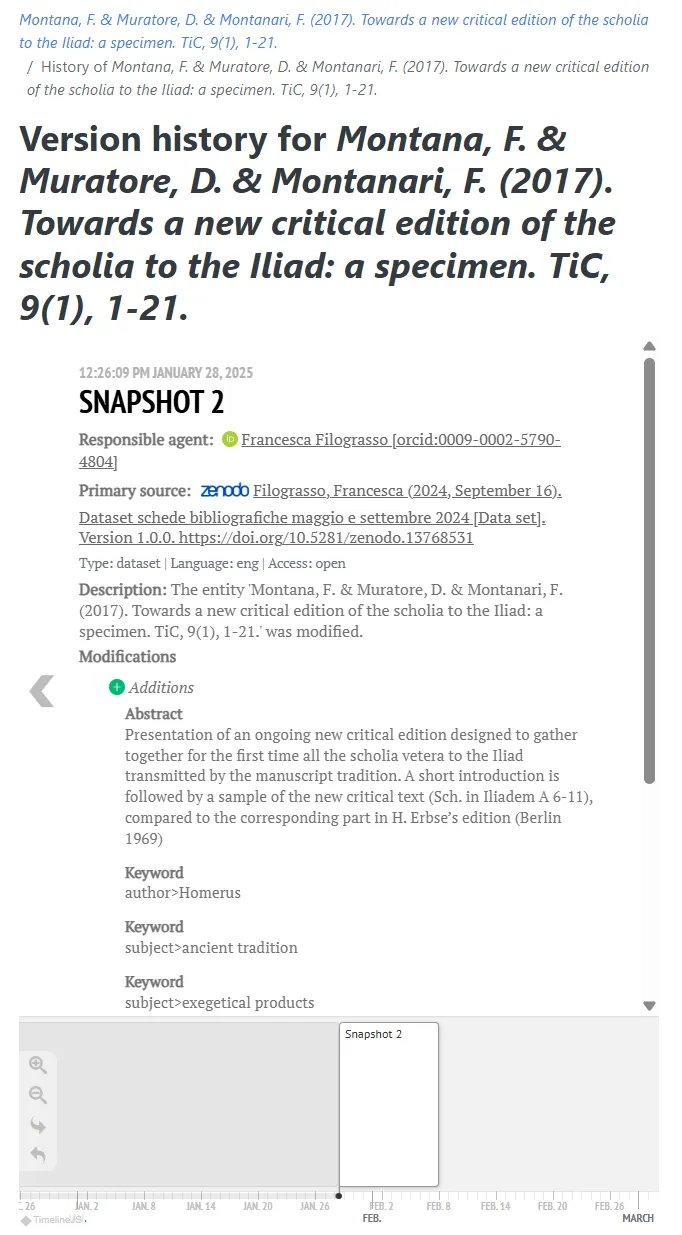
Section titled “Provenance management and change tracking”HERITRACE employs the OpenCitations Data Model (OCDM) extending the PROV Ontology to implement comprehensive provenance management. Every modification is captured as a snapshot with complete metadata including:
- Timestamp of creation/invalidation
- Responsible agent (individual, organization, or automated process)
- Primary data source
- Detailed list of modifications made
Change tracking uses a delta-based approach storing only differences between successive snapshots as SPARQL update queries, enabling efficient storage and precise restoration of previous versions.
![]()
Time machine and time vault
Section titled “Time machine and time vault”The time machine feature provides a timeline interface for managing entity evolution, allowing users to view previous versions and restore earlier states with automatic adjustment of linked resources. The time vault serves as a specialized catalog for deleted entities, enabling recovery when needed.
Intelligent metadata management
Section titled “Intelligent metadata management”- Real-time validation: SHACL-based constraints ensure data consistency and integrity
- Smart disambiguation: Automatic detection of similar entities during creation to prevent duplication
- Dynamic field configuration: Interface adapts based on entity type and defined schemas
- Semantic relationship management: Handle complex relationships between entities with proper validation
Seamless RDF integration
Section titled “Seamless RDF integration”HERITRACE functions effectively out of the box with existing RDF datasets. Simply connect to your triplestore - no data transformation or special import procedures required. The system automatically discovers and displays entities based on their RDF types.
Technical foundation
Section titled “Technical foundation”HERITRACE is built using modern web technologies optimized for semantic data management:
- Backend: Python Flask framework with RDFlib for RDF processing and Time-agnostic Library for managing version reconstruction
- Database: Database-agnostic architecture supporting any RDF triplestore. Tested with Virtuoso and Blazegraph, but also compatible with GraphDB and Apache Jena. Virtuoso is recommended as it is open source and actively maintained, while Blazegraph is no longer maintained
- Frontend: Jinja2 templating engine with React components for interactive elements requiring reactivity
- Standards compliance: Built on RDF, SPARQL, SHACL, and PROV-O standards
- Authentication: ORCID OAuth integration with access control
- Deployment: Docker and Docker Compose support for easy installation
- Customization: SHACL for data model definition, YAML for display rule configuration
Real-world deployment
Section titled “Real-world deployment”HERITRACE is currently deployed in the ParaText project at the University of Bologna, managing bibliographic metadata for textual resources. The system is also planned for adoption by OpenCitations, demonstrating its scalability for large-scale, dynamic datasets in real production environments.