Why pycurl?
When building a SPARQL client, HTTP performance matters. Every query involves an HTTP round-trip, and for applications executing thousands of queries, the choice of HTTP library directly impacts throughput.
We benchmarked six popular Python HTTP libraries against a Virtuoso SPARQL endpoint to make an informed decision. The results clearly favor pycurl.
Benchmark methodology
Section titled “Benchmark methodology”The full benchmark is available at sparql-http-benchmark.
Test setup:
- Virtuoso SPARQL endpoint running in Docker
- Python 3.12+
- 11 runs per test (first run is warmup, discarded)
- 50 iterations per query type
- All libraries configured with equivalent connection pooling and 30-second timeouts
Operations tested:
- Read: SELECT (simple, filtered, with OPTIONAL), ASK, CONSTRUCT
- Write: INSERT DATA, DELETE DATA, UPDATE (DELETE/INSERT)
Results
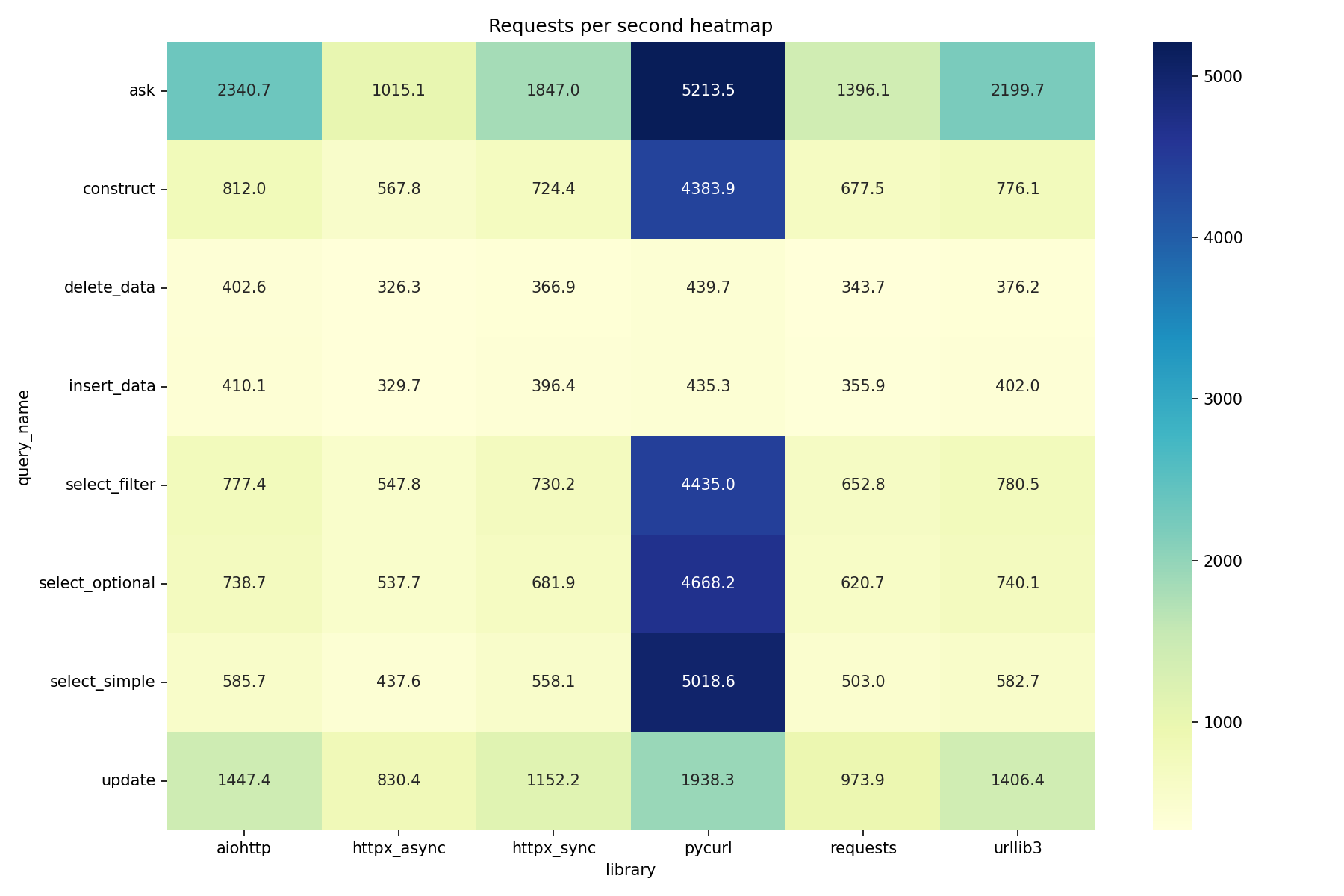
Section titled “Results”Average request time
Section titled “Average request time”| Library | Avg time | Relative |
|---|---|---|
| pycurl | 0.78ms | 1.0x |
| aiohttp | 1.45ms | 1.9x |
| urllib3 | 1.50ms | 1.9x |
| httpx (sync) | 1.61ms | 2.1x |
| requests | 1.78ms | 2.3x |
| httpx (async) | 2.02ms | 2.6x |
pycurl is 2x faster than httpx and 2.3x faster than requests.
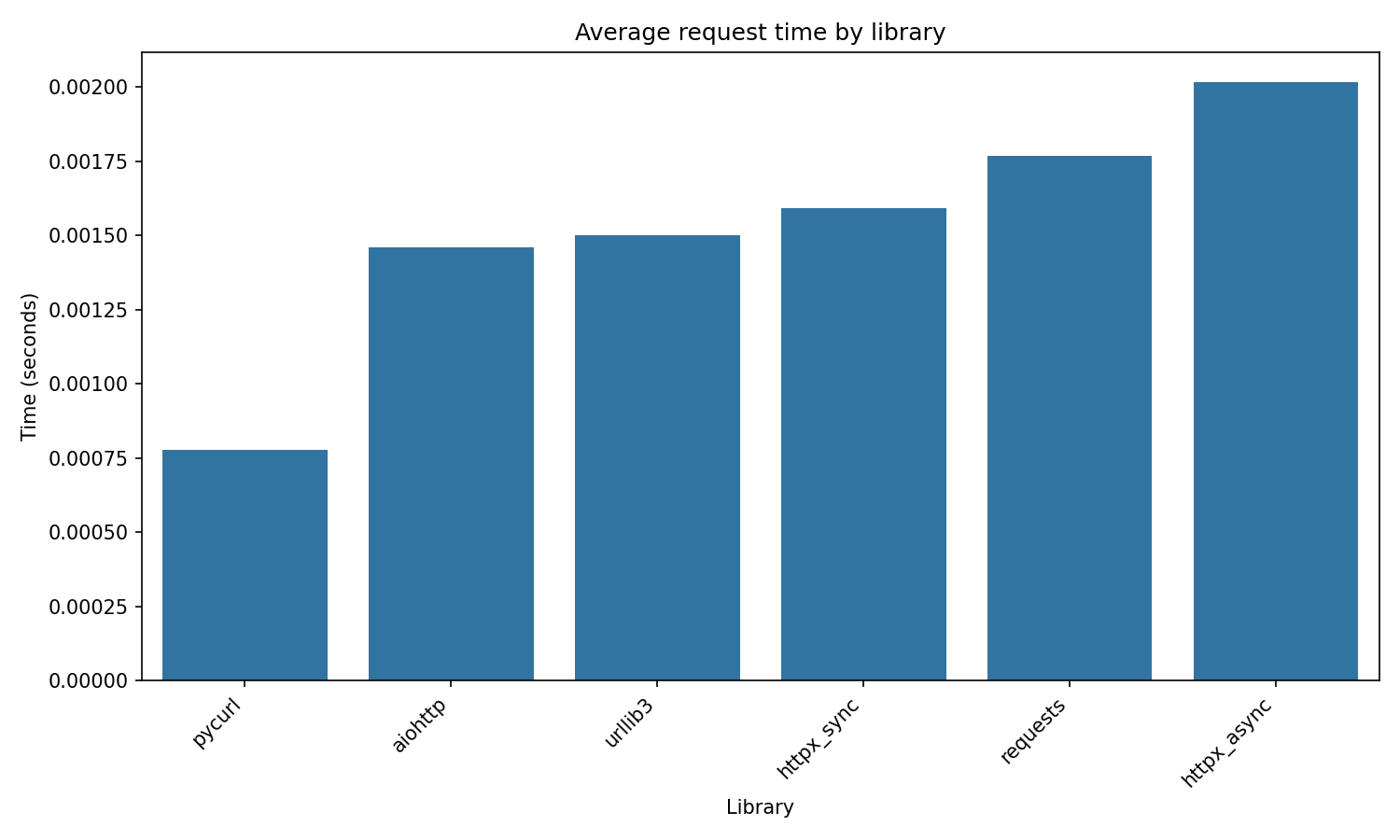
Read operations
Section titled “Read operations”For read-heavy workloads (the typical SPARQL use case), pycurl dominates:
- 5,846 requests/second for simple SELECT queries
- 5-6x higher throughput than competitors
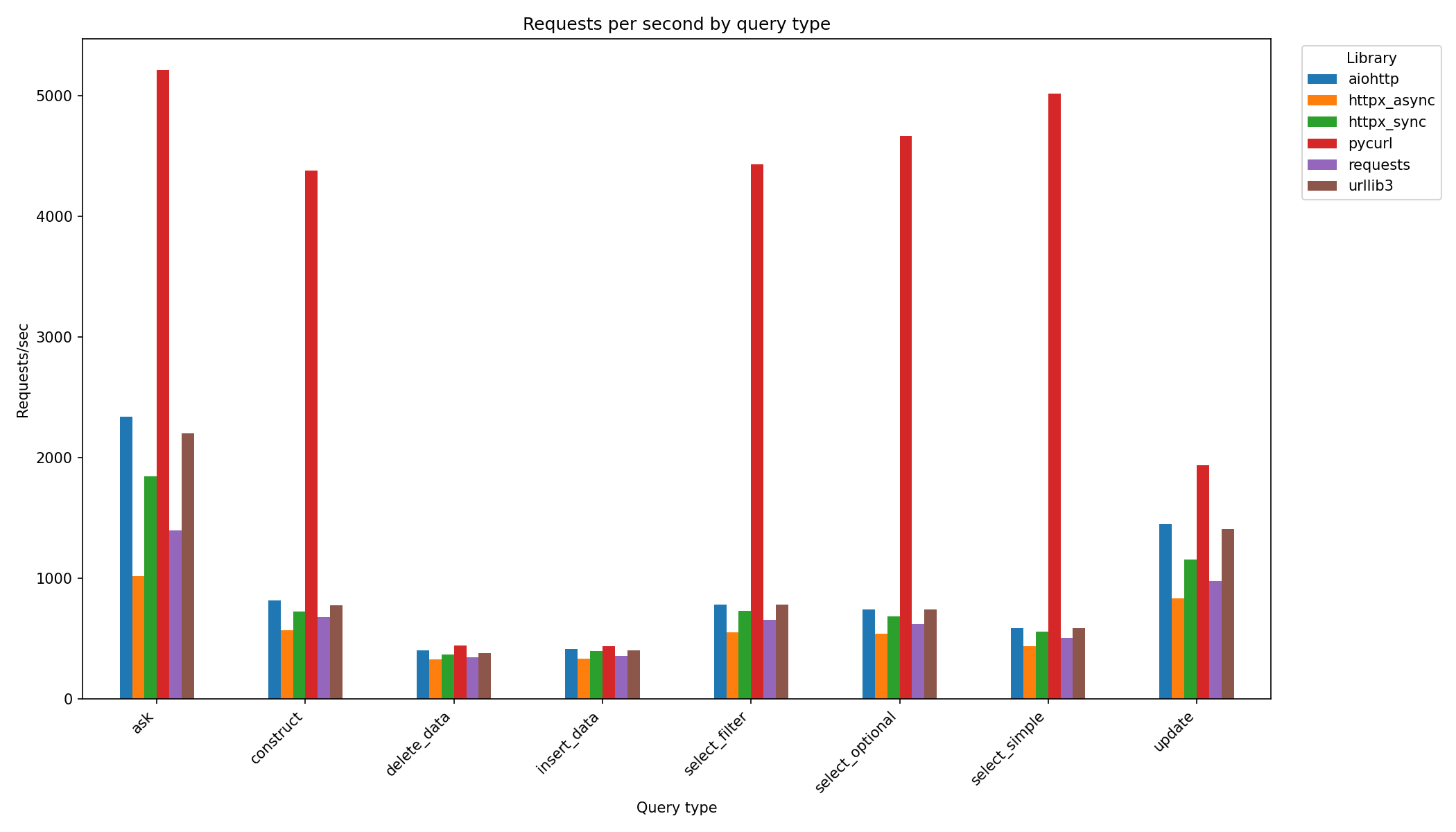
Write operations
Section titled “Write operations”Write operations show convergence across all libraries (300-2,000 req/s). This is expected: the database write mechanism becomes the bottleneck, not HTTP client overhead.
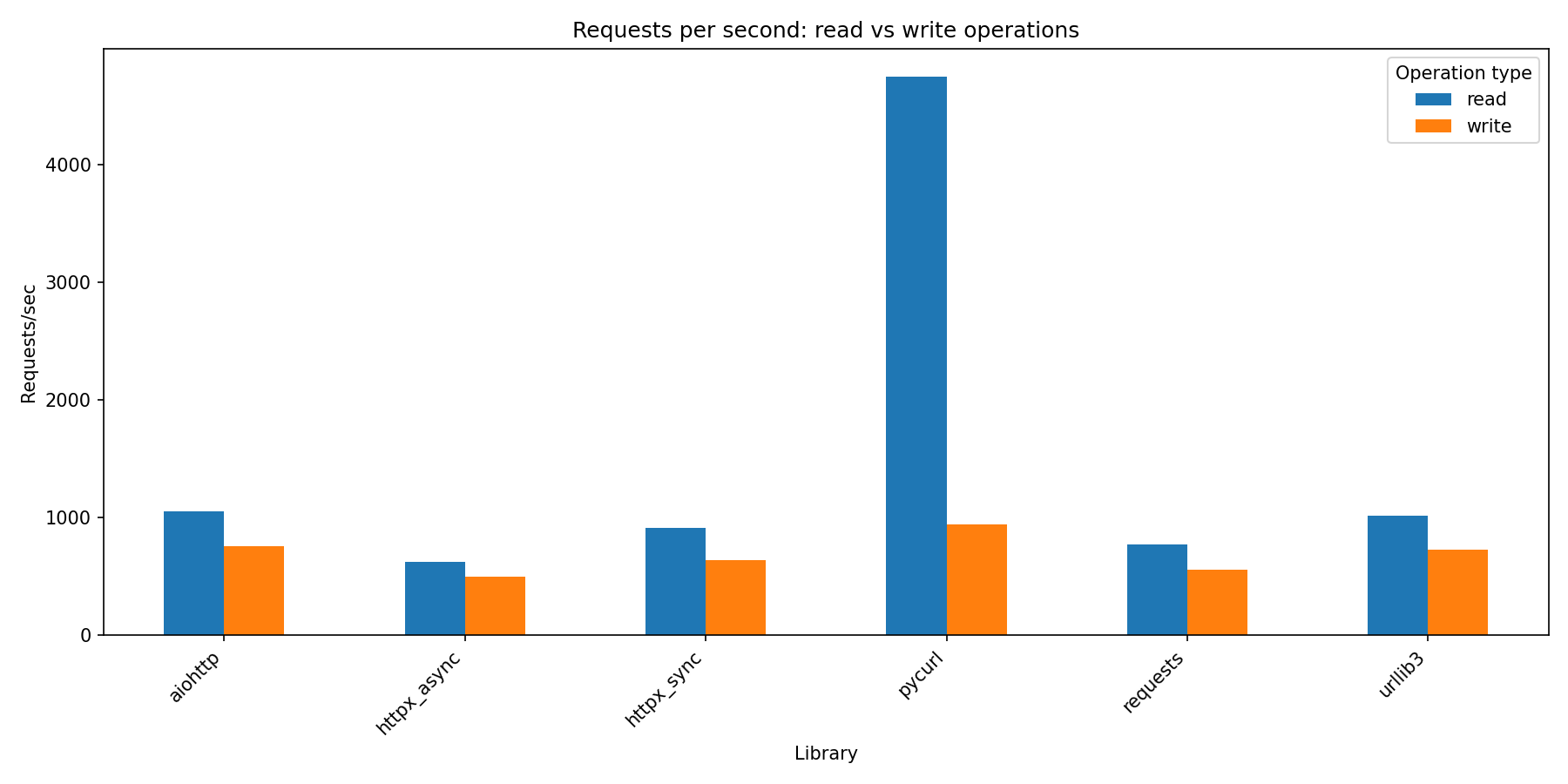
Performance heatmap
Section titled “Performance heatmap”